
Heterogeneous Subgraph Features
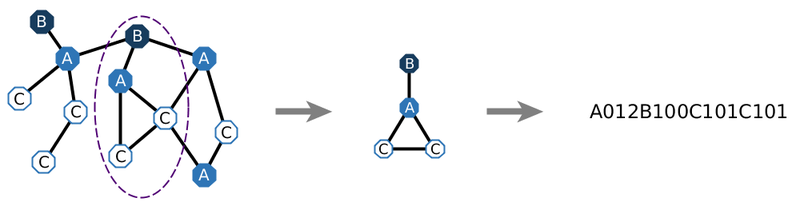
Heterogeneous Subgraph Features
Complex networks and graph-structured data - such as information networks or knowledge graphs - play an increasingly important role in modeling real-world systems due to their utility in representing complex connections. For predictive analyses, the engineering of node features in such networks is of fundamental importance to machine learning applications. However, given such a network, the lack of external information or domain knowledge often introduces the need for features that are based purely on network topology since engineering features by hand is too time consuming or simply not possible. Many node feature extraction approaches have been proposed to address this problem, most prominently so-called node embeddings. However, node embeddings can be difficult to use as they depend on a large number of parameters that need to be tune, so we propose to use subgraph features as an easy-to-use alternative that performs as well or even better in many applications.
Since the heterogeneity of networks (i.e., nodes may have different labels) is often disregarded to simplify the extraction of features, the information that is contained in the topology of heterogeneous networks tends to be disregarded by many feature extraction approaches. To avoid this shortcoming, we generalize the notion of heterogeneity to the subgraph extraction and present an approach for the efficient representation of heterogeneous subgraph features.
The resulting heterogeneous subgraph features are a novel approach to extracting features from heterogeneous networks such as knowledge graphs or information networks for use in predictive machine learning tasks. Conceptually, nodes are simply represented by the counts of the encodings of all subgraphs that occur in the vicinity of the node. Based on an efficient encoding of subgraph representations and fast (pseudo) isomorphism checks, the features can be extracted efficiently and without any parameter tuning. The features then constitute simple key-value pairs that can be used for regression and classification tasks in any machine learning approach. Subsequently, the features can also be used in an importance analysis (e.g., with Random Forests or Gradient Boosting) to deduce which subgraphs represent important functions of the network for the given tasks.
For a more detailed introduction, please take a look at the original publication [pdf], the presentation slides [pdf], or the introductory poster [pdf].
Implementation & Download
A github repository is under construction. In the meantime, we provide an updated and easy-to-use version of the subgraph extraction code for download. The implementation is in C++ with python wrapper for ease of use. For usage instructions, please see the included readme file.
Download C++ / Python implementation [zip]
Publications & References
If you use our code or if you build on our approach, please consider citing us! The paper that describes the extraction of heterogeneous subgraphs was presented at the Workshop on Graph Data Management Experiences &
Systems and Network Data Analytics (GRADES-NDA '18), in conjunction with ACM SIGMOD 2018.
- Andreas Spitz, Diego Costa, Kai Chen, Jan Greulich, Johanna Geiß, Stefan Wiesberg, and Michael Gertz.
Heterogeneous Subgraph Features for Information Networks.
In: Proceedings of the First International ACM SIGMOD Workshop on Graph Data Management Experiences & Systems and Network Data Analytics (GRADES-NDA '18), Houston, TX, USA, June 10 - 15. 2018, 7:1–7:9
[pdf] [acm] [bibtex] [slides] [poster]